Words Inna File
C.K. Haun
Download Version 1.0.1 June 2013
I'm writing another app that requires me to build word lists from text files. I wrote some code to do that, and we'll see where that goes in that other, weird, app. But since I had the word list builder and had a little fun playing with it, I figured I'd throw it into the world, you might have some fun with it. Update: That other app is now done, take a look at the weird Machine Essays.
What it does.
Words Inna File looks through a ASCII/UTF8 stored file and pulls all the unique words from that file, and organizes them into letter groups. Then you can look at those groups.
Excited yet? There's more!
You can also export those lists of unique words into a text file!!!!
Whew, I'll let you catch your breath. No, it doesn't do anything else. But I think it's kinda neat, and someone might actually find a use for it, so I'm putting it out there for y'all to find. I'll let you know here when the other app, that really uses this, is ready. This only works with alphabets that have 26 letters, becasue that's all I care about. And Unicode is right out, export your file to sample to plain text if you want a scan.
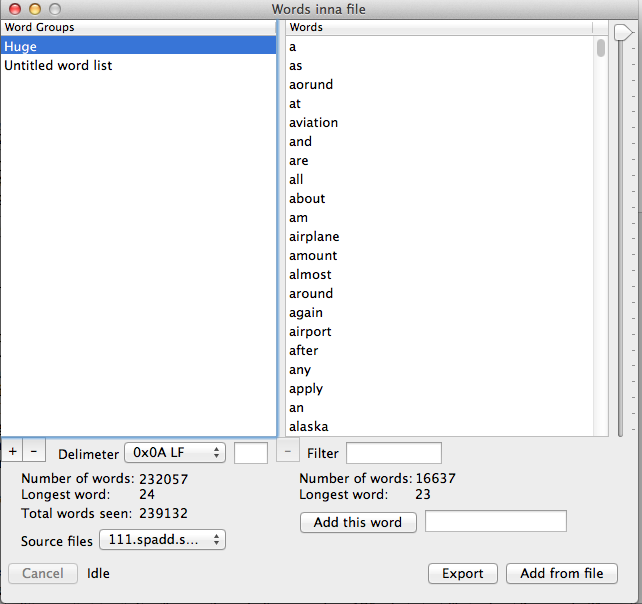 |
There are two tables in the window. The table on the left is the Word Groups table, where you create and manage complete word lists.
The table on the right is the list of words for each letter in the word group. The slider goes to each letter, from A at the top to Z at the bottom.
To start, click the + button under the Word Groups table to create an untitled word group.
You can add words to a word group in two ways, by typing htem in or by scanning a file. Obviously, scanning a file is the intent.
When Words Inna File scans a file it looks for groups of ASCII characters bracketed by a delimter character. By default that character is and ASCII space, hex 0x20. That is set by the Delimter popup button under the Word Group table. There are two other pre-set delimeters in that list, line feed (0x0A) and carrage return (0x0D) that you can select. You can also select other and enter a single hex character in the edit box next to the popup. Only single-character delimters are allowed.
Now go get some words. Click the Add from file button and you'll be prompted to select a file to scan for words.
Note that this can be any type of file you want to look at. Obviously, scanning a text file is the most common use of Words Inna File but it will happily scan a jpeg, a zip, an mp3, whatever. Some interesting things can be found that way.
The scan begins. The scan is actually done on a seperate thread, so scanning very large files, or files with a great many unique words, happens in the background without stopping you from doing other things.
When the scan is done (almost instantly in most cases) the unique words in that file will be displayed in the right hand list.
Thats it! |
Other things to do
- Double-click on a word group name to change it
- You can delete word groups by selecting them in the left hand box and clicking the lower minus button
- You can add words one-by-one by typing them in to the edit box next to the Add this word button, then clicking that button
- You can delete individual words one-by-one by selecting them in the word list and clicking the minus button under that list.
- You can filter the word list, just type characters into the Filter edit box and only those words containg those letters will be in the list
- You can save any word list by selecting it in the list and using the Save menu item
- Same thing with opening them, just use the Open menu item
- Click the Export button and you'll be propmted for a file anem and location, and Words Inna File will save all the unique words in it's lists into one text file.
- The Cancel button will rarely be needed, and will rarely light up. However, tehre are some conditions where a scan might take quite a while, and you might want to cancel it. If the scan is taking a while, the button will be active and you can cancel if you'd like.
- You can merge two word groups by saving both of them to disk, select one in the list, then use Add from file to select the other. I will make this simpler maybe, but I have no idea of anyone will even use this so you need to tell me.
What it's doing
When a new word group is created, 26 empty letter groups are created. When you select a file to add, the file is loaded into memory and handed off to the parser. The parser is a seperate thread. The parser walks through the input file looking for groups of characters seperated by the delimter character. It lower-cases all the ASCII characters it finds(I usually upper case, decided to lower case this time) between delimters, then searches through all the words it has already found to see if this one has been found yet. If it has been found, on to the next letter group. If it has not been found, it's added to that letter group. Continue until the whole file has been processed.
It's pretty fast, I spent a lot of time optimizing it. It will parse through, for example, a 175 mbyte text file in about 3 seconds. The gating item on how long it takes is the number of unique words. The more unique words, the more time it takes to index them. The 175 mybte file I referenced there ends up having only about 16,000 unique words. I have a 2.5 mbyte file with more than 200,000 unique words, and that takes minutes to parse. You'll probably be surprised by how many unique words are in most text.
Scanning is pretty good, but not perfect. It will pick up non-words if you scan something like a mail database, where headers and addresses might look like words.
If this all sounds like a lot of work for nothing, maybe so. But I had fun writing it, and you may have fun playing around with it. Historical note, the 1st version of this was written in 1992, this is much better. email me.
C.K. Haun <TR>
Software Home